
Google Crawler là gì? Được xem là một trong những công cụ quan trọng nhất của Google, Crawler đóng vai trò quan trọng trong việc cập nhật các trang web vào cơ sở dữ liệu của Google và giúp tìm kiếm hiệu quả hơn cho người dùng. Trong bài viết này SGO MEDIA sẽ cùng bạn tìm hiểu về Google Crawler và cách công cụ này hoạt động để thu thập dữ liệu từ các website nhé.
Google Crawler là gì?
Google Crawler là một phần của Googlebot – một chương trình tự động của Google được sử dụng để thu thập thông tin từ các trang web trên internet. Google Crawler sẽ duyệt qua các trang web và thu thập thông tin về nội dung, liên kết và các thông tin khác để cập nhật vào cơ sở dữ liệu của Google. Quá trình này giúp Google hiển thị các kết quả tìm kiếm chính xác và liên quan đến từ khóa tìm kiếm của người dùng.
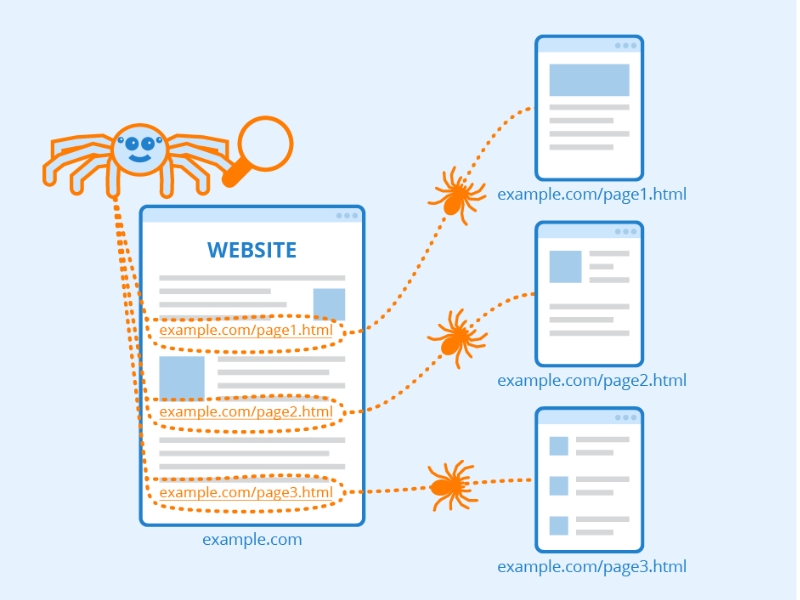
Google Crawler quan trọng như thế nào?
Google Crawler là một chương trình máy tính của Google, có nhiệm vụ duyệt web và thu thập thông tin về các trang web. Google Crawler còn được gọi là Googlebot, spider, robot hay bot. Công cụ này là một yếu tố quan trọng trong quá trình tối ưu hóa công cụ tìm kiếm (SEO), vì sẽ ảnh hưởng đến khả năng xuất hiện của trang web trên kết quả tìm kiếm của Google.
Website sẽ được thêm vào chỉ mục Google nhanh hơn, thu hút nhiều lượt truy cập hơn và có xếp hạng cao hơn trong kết quả tìm kiếm trên trang (SERPs).

Trình thu thập dữ liệu của Google hoạt động như thế nào?
Nhiệm vụ chính của Crawler là tìm kiếm thông tin trên mạng, xếp loại và phân loại các danh mục để mọi người có thể dễ dàng tìm thấy thông tin mà họ cần khi ghé thăm.Trình thu thập dữ liệu của Google hoạt động theo ba giai đoạn chính như sau:
Crawling (Thu thập thông tin)
Crawling là quá trình mà trình thu thập dữ liệu của Google đi qua các trang web trên Internet để tìm kiếm thông tin mới và cập nhật. Để làm điều này, Google sử dụng các robot tự động gọi là web crawlers hoặc Googlebot. Những con bot này sẽ bắt đầu từ trang web gốc đã được biết đến (chẳng hạn như trang chủ của Google), sau đó theo dấu liên kết và đi qua các trang liên kết từ đó để lục lọi qua toàn bộ mạng.
Rendering (Hiển thị)
Sau khi thu thập thông tin qua các trang web, tiến hành giai đoạn hiển thị. Trong giai đoạn này, Googlebot sẽ cố gắng trích xuất thông tin và dữ liệu từ các trang web mà nó đã lục lọi. Điều này bao gồm việc tải và hiển thị các phần tử của trang web như văn bản, hình ảnh, video, mã JavaScript và CSS. Hiển thị trang web cho phép Googlebot hiểu cấu trúc và nội dung của trang để tiếp tục xử lý dữ liệu tiếp theo.
Indexing (Lập chỉ mục)
Sau khi dữ liệu của website đã được hiển thị và trích xuất, các thông tin này sẽ được thêm vào một cơ sở dữ liệu lớn gọi là chỉ mục của Google. Chỉ mục là một tập hợp các thông tin thu thập từ hàng tỷ trang web trên Internet. Quá trình lập chỉ mục giúp Google xây dựng một cơ sở dữ liệu toàn diện về các website và nội dung. Khi người dùng thực hiện một tìm kiếm, Google sẽ sử dụng chỉ mục này để tìm kiếm và hiển thị các kết quả liên quan và phù hợp nhất với truy vấn của họ.

Cách để giúp crawl trang web của bạn nhanh nhất
Hãy cùng tìm hiểu các cách đơn giản nhưng hiệu quả để giúp trang web của bạn được crawl nhanh chóng và hiệu quả nhất.
Google News
Khi website của bạn cung cấp các nội dung về tin tức, hãy đăng ký với Google News. Googlebot sẽ ưu tiên thu thập thông tin các trang web có liên quan đến tin tức nhanh hơn, giúp trang web của bạn xuất hiện trong kết quả tìm kiếm ngay khi các sự kiện mới diễn ra.

Rank Math
Rank Math là một plugin SEO mạnh mẽ dành cho WordPress. Sử dụng công cụ này để tối ưu hóa các phần quan trọng của trang web của bạn, bao gồm tiêu đề, mô tả, thẻ hình ảnh, URL và nội dung.
Sử dụng tính năng nghiên cứu từ khóa của Rank Math để tìm từ khóa phù hợp và sử dụng chúng trong nội dung của bạn.

Google Search Console
Google Search Console (trước đây là Google Webmaster Tools) là một công cụ miễn phí cung cấp thông tin vô cùng quan trọng về tình trạng và hiệu suất website của bạn trên Google Search. Bằng cách đăng ký website của bạn vào Google Search Console, bạn có thể theo dõi số lượng trang được “lục lọi”, kiểm tra lỗi trên trang, tối ưu robots.txt và sitemap.xml, và yêu cầu Google thu thập dữ liệu lại từ các trang quan trọng.

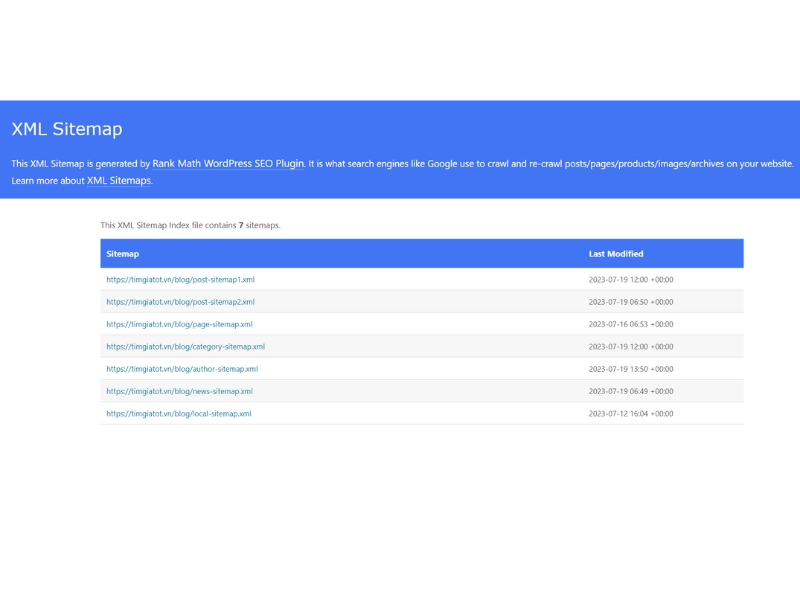
XML Sitemap
XML Sitemap là danh sách tất cả các trang quan trọng trên website của bạn mà bạn muốn các công cụ tìm kiếm thu thập thông tin. Đảm bảo rằng bạn đã tạo một Sitemap chính xác và gửi qua Google Search Console và Bing Webmaster Tools để giúp các công cụ tìm kiếm hiểu cấu trúc trang web của bạn và Crawler các trang quan trọng hơn.
Robots.txt
Robots.txt là tệp văn bản đơn giản giúp bạn chỉ định các trang hoặc thư mục mà bạn muốn ngăn các trình thu thập dữ liệu thu thập thông tin. Chỉnh sửa Robots.txt của bạn sao cho các trang không quan trọng hoặc không cần thiết không bị Crawler, và chỉ tập trung vào thu thập dữ liệu từ các trang quan trọng hơn.

Fetch as Google
Tính năng Fetch as Google, cho phép bạn yêu cầu Googlebot thu thập dữ liệu lại các trang cụ thể của bạn. Điều này hữu ích khi bạn muốn trang mới hoặc trang đã cập nhật được Crawler và lập chỉ mục nhanh chóng.
Những lỗi thường xảy ra trong quá trình Google thu thập dữ liệu từ website
Đây là một số lỗi phổ biến làm cho Googlebot không thể crawl website mà bạn nên lưu ý:
- Lỗi DNS: Lỗi này xảy ra khi con bot Google không thể tìm thấy tên miền của bạn. Điều này có thể do tên miền của bạn bị sai hoặc bị xóa khỏi hệ thống DNS. Để khắc phục lỗi này, bạn nên kiểm tra lại tên miền của mình, đảm bảo rằng đã được đăng ký và cài đặt đúng cách.
- Lỗi Robots.txt: Tệp robots.txt là một tệp cấu hình trên trang web của bạn, cho biết cho robot của các công cụ tìm kiếm như Googlebot biết những phần của trang web nào không được phép crawl. Nếu tệp robots.txt của bạn không được cấu hình đúng hoặc bị sai sót, thuật toán sẽ không thể crawl trang web của bạn. Để khắc phục lỗi này, bạn nên kiểm tra lại tệp robots.txt của mình và xác định cấu hình đã chính xác.
- Lỗi HTTP: Lỗi này xảy ra khi trang web của bạn trả về mã lỗi HTTP, như mã lỗi 404 (không tìm thấy trang). Nếu Googlebot không thể truy cập được trang web của bạn, nó sẽ không thể crawl.
- Lỗi liên quan đến SSL: Lỗi này xảy ra khi trang web của bạn sử dụng SSL nhưng chứng chỉ SSL không hợp lệ hoặc đã hết hạn. Nếu chứng chỉ SSL của bạn đã hết hạn hoặc không hợp lệ, Googlebot sẽ không thể truy cập được trang web của bạn và crawl. Để khắc phục lỗi này, bạn nên kiểm tra lại chứng chỉ SSL của mình và đảm bảo rằng đã được cài đặt đúng cách.
- Lỗi liên quan đến JavaScript: Lỗi này xảy ra khi trang web của bạn sử dụng JavaScript để hiển thị nội dung, nhưng Googlebot không thể đọc được JavaScript. Nếu Googlebot không thể đọc được nội dung của trang web của bạn, nó sẽ không thể crawl. Để khắc phục lỗi này, bạn nên kiểm tra lại trang web của mình và đảm bảo rằng nội dung được hiển thị bằng JavaScript có thể được đọc bởi Googlebot.
Google Crawler xem các trang như thế nào?
Khi sử dụng công cụ tìm kiếm Google, chúng ta có thể tìm thấy hàng triệu website khác nhau. Tuy nhiên, bạn đã bao giờ tự hỏi Google Crawler làm thế nào để xem và đánh giá tất cả các trang web đó? Dưới đây là các cách thu thập dữ liệu của con bot Google mà bạn nên biết:
Thu thập trên thiết bị di động và máy tính để bàn
Googlebot có thể “xem” trang web của bạn thông qua hai crawler con: Googlebot Desktop và Googlebot Smartphone. Việc phân loại này là cần thiết để lập chỉ mục các trang cho cả kết quả tìm kiếm trên máy tính để bàn và trên điện thoại di động.
Google Crawler không phân biệt giữa thiết bị di động và máy tính để bàn khi thu thập thông tin từ trang web. Googlebot sẽ truy cập trang web từ cả hai loại thiết bị để thu thập dữ liệu. Google hiểu rằng có sự khác biệt giữa trải nghiệm người dùng trên thiết bị di động và máy tính để bàn, vì vậy, trang web được thiết kế phản hồi (responsive) và tương thích trên cả hai loại thiết bị sẽ được đánh giá cao hơn trong kết quả tìm kiếm di động.
Thu thập HTML và JavaScript
Khi Googlebot thu thập dữ liệu của website, sẽ tiến hành thu thập thông tin từ HTML và JavaScript của trang. HTML (HyperText Markup Language) là ngôn ngữ lập trình được sử dụng để tạo cấu trúc và nội dung của trang web. Googlebot sẽ thu thập dữ liệu và trích xuất văn bản, hình ảnh và liên kết từ HTML để hiểu cấu trúc và nội dung của trang.
Ngoài ra, Googlebot cũng hiểu và thực thi JavaScript của website. JavaScript là một ngôn ngữ lập trình phổ biến được sử dụng để tạo các tính năng tương tác và động trên trang web. Khi Googlebot thực thi JavaScript, có thể hiểu được các phần nội dung được tạo ra hoặc thay đổi bằng JavaScript. Điều này giúp Googlebot hiểu rõ hơn về cách website hoạt động và đảm bảo rằng các nội dung tương tác và hành động được xem xét trong quá trình thu thập dữ liệu.

Điều gì sẽ ảnh hưởng đến hành vi của Google Crawler?
Hành vi của Google Crawler có thể bị ảnh hưởng bởi nhiều yếu tố khác nhau, dưới đây là các yếu có thể ảnh hưởng đến hành vi của con bot Google mà bạn nên biết:
Liên kết nội bộ và backlink
Liên kết nội bộ giúp Google Crawler hiểu cấu trúc của website và giúp thu thập dữ liệu từ các trang quan trọng hơn.
Backlink (liên kết từ các trang web khác trỏ về trang web của bạn) giúp tăng đáng kể độ uy tín của website và cải thiện khả năng xếp hạng trong kết quả tìm kiếm.
Khả năng click chuột (CTR)
Là tỷ lệ giữa số lần người dùng nhấp chuột vào kết quả tìm kiếm của trang web và số lượt hiển thị kết quả đó. CTR cao sẽ gợi ý rằng website cung cấp thông tin hữu ích cho người dùng, từ đó sẽ giúp cải thiện xếp hạng và tần suất thu thập dữ liệu của Google Crawler.
Sơ đồ của website
Sơ đồ của website (sitemap) giúp Google Crawler hiểu cấu trúc và các liên kết quan trọng trên trang web của bạn. Việc cung cấp sơ đồ trang web giúp tối ưu hóa tốc độ thu thập dữ liệu và đảm bảo tất cả các trang quan trọng được thu thập dữ liệu.
Lập chỉ mục trang
Google Crawler sẽ thu thập dữ liệu và lập chỉ mục cho website của bạn vào cơ sở dữ liệu của Google. Việc lập chỉ mục đúng và hiệu quả đảm bảo rằng trang web của bạn xuất hiện trong kết quả tìm kiếm liên quan và chất lượng.
Có phải tất cả website đều cho phép Google Crawler hoạt động?
Website sẽ có thể hạn chế quyền hạn cho Google Crawler thông qua tệp robots.txt. Nếu các trang quan trọng bị ngăn truy cập, con bot của Google không thể lục lọi chúng và điều này ảnh hưởng đến xếp hạng của trang web.
Thời gian website có thể xuất hiện trên kết quả tìm kiếm?
Thời gian xuất hiện trên kết quả tìm kiếm phụ thuộc vào tần suất “lục lọi” và cập nhật nội dung của website. Các trang web thường xuyên được thu thập dữ liệu và cập nhật sẽ xuất hiện nhanh chóng hơn trong kết quả tìm kiếm.
Xem thêm: Báo giá dịch vụ SEO Tổng thể website
Trùng lặp nội dung
Googlebot sẽ phát hiện và xử lý trùng lặp nội dung trên các trang web. Nếu nội dung trùng lặp quá nhiều hay được coi là spam, có thể ảnh hưởng đến việc thu thập dữ liệu và xếp hạng trang web của bạn trên kết quả tìm kiếm.
Cấu trúc URL
Cấu trúc URL tốt giúp con bot của google hiểu rõ hơn về nội dung của trang và quan hệ giữa các trang. Sử dụng các từ khóa thích hợp trong URL giúp Googlebot dễ dàng nhận diện chủ đề của trang hơn.

Kết luận
Qua bài viết này, SGO Media hy vọng bạn đã hiểu được Google Crawler là gì? Và có cái nhìn rõ nhất về trình thu thập dữ liệu của Google này. Với cơ chế hoạt động thông minh và hiệu quả của mình, Google Crawler đã đóng vai trò quan trọng trong việc cập nhật các website và giúp tìm kiếm hiệu quả hơn cho người dùng. Và có thể thấy việc tìm hiểu về Google Crawler là rất cần thiết đối với những người làm việc trong lĩnh vực SEO và digital marketing.
Ngoài ra, nếu bạn đang có nhu cầu tư vấn về các giải pháp SEO website, thiết kế website, quản trị fanpage, hay muốn tham khảo các giải pháp về Marketing,… Hãy nhấc máy lên và liên hệ ngay với sgomedia.vn qua hotline 0912.399.322 hoặc Fanpage để nhận được sự hỗ trợ và tư vấn sớm nhất. Với kinh nghiệm nhiều năm trong lĩnh vực SEO, chúng tôi cam kết mang đến cho khách hàng những dịch vụ chất lượng và đem lại hiệu quả tốt nhất.



